Generative AI Use Cases and Applications
By A3Logics
/ October 22, 2024
AI or Artificial Intelligence has come a long way in the last ten years. What started as problem-solving software is...
Read More

An enveloping darkness of the world was lifted with the introduction of electric light, revealing it in a transformational way. These days, we are at the beginning of a similar revolution, but it is happening inside the complex neural network circuits of LLMs, rather than in the actual world. The foundation of complex language creation and understanding in the quickly developing field of generative artificial intelligence is Large Language Models (LLMs).
The potential of LLMs must not be limited, much like the freeing force of electricity. Open-source LLMs emerge as guardians to ensure widespread distribution and promote equity and creativity in language power. We see innovation in the open-source space, but we also see a call to bring humanity’s collective intelligence together. By removing obstacles related to language and access, LLMs have the potential to democratize education. They have the power to transform a variety of industries, including healthcare and law, by making specialized knowledge widely available.
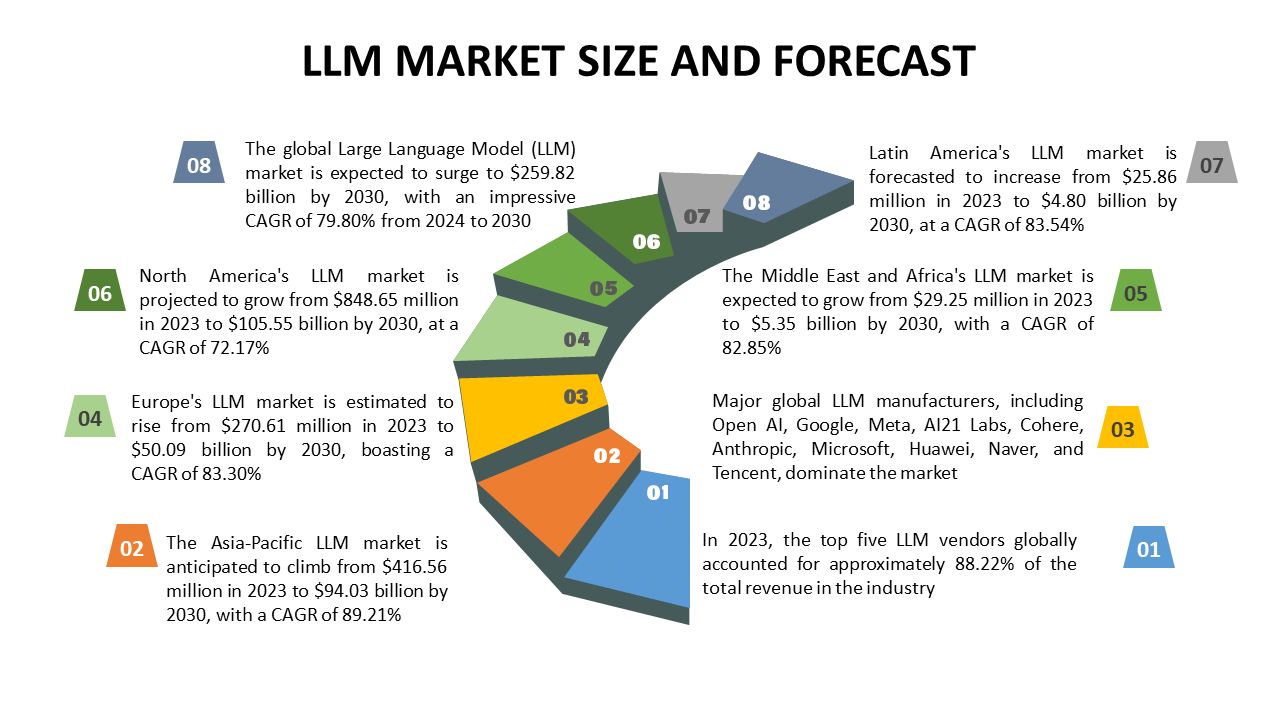
This revolutionary idea is not some far-off dream; rather, it is a reality that is growing thanks to the open-source community. The market for large language models is expected to reach a valuation of USD 4.35 billion globally by 2023. Grand view research anticipates that Large language model development will expand at a compound annual growth rate (CAGR) of 35.9% between 2024 and 2030.
This blog seeks to dissect the subtleties of the top 10 LLMs that will be ruling the industry in 2024. A detailed look at the technologies that are transforming the way we use language will be provided soon.
Large language models (LLMs) are deep learning algorithms known for handling a wide range of natural language processing (NLP) tasks. Massive datasets train huge language models derived from transformer models. This gives them the ability to comprehend, translate, forecast, or produce text or other content.
Neural networks, computer systems modeled after the human brain, are another name for large language models. Similar to neurons, these neural networks function by employing a layered network of nodes.
Large language models can do a wide range of activities such as deciphering structures, creating software code, and more, apart from teaching human languages to generative AI applications. They are like the human brain need to pre-train and then fine-tune to handle
Industries like healthcare, finance, and entertainment use large language models for chatbots, AI assistants, translation, and other NLP applications to utilize their problem-solving skills. Much like a human has many memories from its training, a large language model similarly has a huge number of parameters. Consider these settings to be the knowledge base of the model.
A large language model’s most popular architecture is the transformer model. An encoder plus a decoder make up this system. A transformer model first tokenizing the input to find links between tokens and then simultaneously solves mathematical equations. When the computer is asked the same question, it can now recognize patterns just like a person would.
Compared to AI large language models, such as lengthy short-term memory models, transformer models can learn more quickly because they use self-attention mechanisms. Self-attention is attributed to the ability of the transformer model to make predictions, taking into account various segments of the sequence.
There are many LLMs available now, and they all have their advantages and disadvantages. Each AI system can produce natural language texts on a wide range of subjects with ease. The AI model has grasped the intricacy of natural language patterns and structures through training on large amounts of text data from many sources.
LLMs provide significant hurdles even though they perform quite well in applications including sentiment analysis solutions, machine translation, question answering, and text summarization. They consist of technological, social, ethical, and environmental factors. Performance, scalability, efficiency, adaptability, and cost are the criteria used to evaluate the top 10 LLMs.
EleutherAI is the developer of the open-source LLM AI GPT-NeoX. The architecture of this autoregressive transformer decoder model mostly adheres to GPT-3, with a few significant exceptions. There are 20 billion parameters in the model.
GPT-NeoX is especially effective in few-shot reasoning, which makes the model better suited for specific applications like code creation.
This model enables the development of applications like content creation, code generation, text summarization, paraphrasing, text auto-correction, text auto-completion, and chatbots. Additionally, it can be used for accomplishing unconditional and conditional text production.
The model’s size makes inference most cost-effective on two RTX 3090 Tis or one A6000 GPU while fine-tuning necessitates much more processing power. According to the GPT-NeoX models Github project, you need to have
Deployment of GPT-NeoX in its current state is not intended. It cannot be used for interactions with people without supervision and is not a product.
Because GPT-NeoX-20B is only available in English, it cannot be used to translate or create text in other languages. It can also be difficult for some users to deploy because it needs sophisticated gear.
Meta AI created LLaMA 2, the follow-up to their open-source LLM. They have pre-trained and refined the models in this collection, with parameters ranging from 7 billion to 70 billion.
After training on 2 trillion tokens, the model’s context length was doubled compared to LLaMA 1, and the output’s accuracy and quality were enhanced.
On a variety of external benchmarks, such as knowledge, coding, reasoning, and skill exams, it performs better than competing open-source language models.
Models like Llama Chat, which makes use of over a million human annotations and publicly accessible instruction datasets, are among them. In addition, Code Llama—a code creation model trained on 500 billion code tokens—is included. Typescript (JavaScript), Python, C++, Java, PHP, C#, and Bash are among the popular programming languages supported by it.
By collaborating with Microsoft, Meta AI, a top artificial intelligence solutions company, has made LLaMA 2 accessible in the Azure AI model library, allowing cloud-native developers to utilize it while building on Microsoft Azure. Developers are given a smooth workflow for delivering generative AI services to clients on a variety of platforms. The design of the system allows it to operate locally on Windows.
BigScience created BLOOM, an innovative open-source LLM. BLOOM has 176 billion parameters and can produce text in 13 computer languages and 46 natural languages. The ROOTS corpus is used for training. As a result, it is the biggest open multilingual language model in existence. Additionally, it incorporates a large number of underrepresented languages into its teaching, including Arabic, French, and Spanish, making it a more inclusive model.
Over 1000 scholars from over 70 nations collaborated to create BLOOM over a year. Researchers executed the project with total transparency, disclosing information on the data used for training, the difficulties encountered during development, and the methods used to assess the system’s effectiveness.
Google’s BERT is an open-source LLM that is transforming natural language processing solutions. Because of its special bidirectional training, it can take in information from text context from both sides at once.
BERT is distinguished by its masked language model (MLM) goal and transformer-based architecture. By guessing the original shapes of input tokens from context, it hides them. BERT can understand word meanings more thoroughly thanks to this bidirectional information flow.
The introduction of Salesforce’s XGen-7B (7 billion parameters) into the LLM development companies represents a major advancement in the industry.
The typical 2,000-token limit is greatly exceeded by XGen-7B’s capacity to process up to 8,000 tokens. This wider range is essential for jobs like in-depth question-answering, thorough summarization, and elaborate conversations that require a deep comprehension of longer narratives.
The model trained a wide range of datasets, including instructional content, to gain a sophisticated comprehension of instructions. Variants like XGen-7B-8K-base and XGen-7B-inst, which have large context lengths and include instructional data, are optimized for specific activities and exhibit higher efficacy.
A demanding two-stage training approach involving 1.5 trillion tokens was applied to XGen-7B. This unique combination of code data and natural language allows the model to perform well in both linguistic and code-generation tasks.
It also investigated “loss spikes” during training, adhering to the LLaMA training recipe and architecture, demonstrating a dedication to taking on challenging problems in model training and optimization.
Hugging Face Transformers provide access to the flexible XGen-7B, which works with several platforms including Amazon Web Services. Though it has advanced capabilities, it is not impervious to common obstacles in the field of LLMs, such as biases, toxicity, and hallucinations.
Meta AI research has developed an open-source LLM with 175 billion parameters called OPT-175B. The training carbon footprint of GPT-3 is seven times larger than what the model needs and GPT-3 performs similarly to the model despite being trained on a dataset of 180 billion tokens.
The OPT-175B is a pre-trained transformer designed solely for decoding. It intends to replicate the performance and size of the GPT-3 class of machines. It is part of a series of models with parameters ranging from 125 million to 175 billion. The model has impressive zero- and few-shot learning capabilities. The Megatron-LM configuration was used to train it.
An artificial intelligence development company is excited about the introduction of OPT-175B because it gives researchers access to a potent LLM that has never been possible before. It is important to note, nevertheless, that because of the substantial computational resources needed, even though the release brings an unprecedented degree of openness and transparency to the construction of LLMs, it does not democratize them.
With an astounding 180 billion parameters, Falcon-180B, created by the Technology Innovation Institute (TII), is popular among Large Language Models (LLMs). In terms of size and power, it surpasses many of its peers.
Strong as a causal decoder-only model, Falcon-180B can produce text that makes sense and is relevant to the situation. Being multilingual, it can speak English, German, Spanish, and French in addition to having some proficiency in other European languages.
The model gains a wide grasp of various content through its training on the RefinedWeb dataset, which is a representative corpus of the web, in conjunction with curated data. Tasks like thinking, coding, language competence tests, and knowledge exams highlight its adaptability.
The training of Falcon-180B required a significant investment of computational resources; it took two months and 384 GPUs on AWS. A major advance, the 3.5 trillion token huge data corpus quadruples the data volume used for models such as LLaMA.
Its cutting-edge design has multi-query attention, which maximizes memory bandwidth and increases inference efficiency.
Researchers and developers can access Falcon-180B, a flexible tool, through Hugging Face Transformers. Falcon-180B also connects with PyTorch 2.0. Both commercial applications and scholarly studies can utilize Falcon-180B.
In the AI community, Falcon-180B has received praise for both its functionality and the openness of its development. It even comes close to matching the power of GPT-4 and fights brilliantly against industry titans like Google’s Bard ( Now Gemini).
Mistral AI created the open-source LLM known as Mistral 7B. It’s a 7.3 billion parameter model that beats Llama 1 34B on numerous benchmarks and beats Llama 2 13B on all of them. The model may be used for coding challenges as well as English language activities, which makes it a flexible generative AI tool with many uses.
In under three months, the Mistral AI team established a high-performance MLops stack and created a complex data processing pipeline from the ground up for Mistral 7B. To facilitate faster inference, the model employs Grouped-query attention (GQA) and employs a fixed attention span to maximize memory use during inference. This keeps Mistral 7B resource-efficient while preserving model quality by enabling it to save half of the cache RAM.
Mistral 7B is available for use on multiple platforms, including Baseten, HuggingFace, Sagemaker Jumpstart, Replicate, and Vertex AI. The model is freely available for business and research contexts thanks to its Apache 2.0 license.
AI has advanced significantly with the release of CodeGen, an open-source Large Language Model (LLM) designed for program synthesis. It competes with high-end models such as OpenAI’s Codex by being designed to understand and generate code in multiple programming languages. Its primary use is in developing programs from descriptions or examples of large language models due to its unique capability to transform English prompts into executable code using prompt engineering services.
CodeGen trained on English text from The Pile, multilingual data from BigQuery, and Python code from BigPython using a blend of natural and programming languages. CodeGen-NL for natural language, CodeGen-MULTI for multilingual, and CodeGen-MONO for Python are the specific versions that emerged from this varied training.
The model was trained in a range of sizes, with parameter counts ranging from 350 million to 16.1 billion, facilitating a thorough comparison with other LLMs. CodeGen is available via Hugging Face Transformers and other platforms. The Apache-2.0 license licenses it, permitting both commercial and research use, and it allows for a variety of coding projects. It further democratizes access to advanced LLMs by making its training library, JAXFORMER, and model checkpoints open-sourced.
The LLaMA concept gave rise to an inventive open-source LLM named Vicuna, created by LMSYS. Initially designed as a chat assistant, Vicuna has since become a significant contributor to language model and chatbot development.
Vicuna provides two versions, the most recent of which is Vicuna-13B v1.3. Vicuna-13B is notable for its training methodology, which leverages about 125K talks from ShareGPT.com. This increases the relevance and application of the model by ensuring a dataset that replicates interactions found in the actual world.
Vicuna’s creation fills a gap left by proprietary models such as ChatGPT: more transparency in the architecture and better training of chatbots.
Vicuna’s development tackles the gap that proprietary models like ChatGPT, a large language model, frequently leave behind in terms of chatbot training and architecture transparency. With 70K user-shared discussions, its training is based on Stanford’s Alpaca project framework. It is modified to meet Vicuna’s unique needs for context duration and data quality.
Vicuna is a user-friendly tool that is accessible using LMSYS APIs and command-line interfaces. Comprehensive instructions are available on GitHub. Evaluation of this model is rigorous using human preference testing and conventional benchmarks.

Notwithstanding these drawbacks, LLM’s remarkable and ongoing progress in the tech industry has created exciting opportunities in a wide range of fields. What comes next is a question that is bound to arise. What does an LLM cover? This field’s future research will probably concentrate on a few main areas:
Developers are creating Large Language Models (LLMs) specifically for particular fields or occupations, such as engineering, law, and medicine. The main focus of current LLM work is on methods for fine-tuning models to achieve improved performance on specialized tasks.
We are still improving the interpretation and integration of several modalities, such as text, images, audio, and possibly other sensory inputs. Additionally, multimodal LLM’s features would enhance the model’s capacity to produce and interpret data in many modalities.
The use of LLMs unethically and bias are major topics. Researchers and practitioners are actively implementing techniques to reduce linguistic biases and incorporate moral issues into LLM training and application.
Also Read: Ethics and Privacy in AI Development
The generic use of LLM at the moment can result in ambiguity and lack of context. Soon, users are expected to customize their preferences with the assistance of LLMs to accommodate personal tastes. Developers are working on personalized learning techniques to enhance the user experience and achieve this objective. Additionally, they are implementing continuous learning mechanisms to keep models up-to-date and relevant.
LLMs are expected to broaden their language support by actively adding new languages and dialects to their repertoire and refining their usage. This will increase the usage of LLMs’ accessibility and inclusivity on a worldwide scale.
By designing LLMs for deployment on edge devices, you may make them more accessible and less reliant on cloud-based solutions, which will boost efficiency and privacy.
Combining different AI models can improve functionality and produce a more thorough approach to problem-solving.
Putting security mechanisms in place and strengthening their resistance to adversarial attacks, and false information, and both can better safeguard LLMs against potentially harmful uses of the technology.
Improving the effectiveness of model architectures and training techniques will boost LLM capability. Ensemble learning combines several models, systematically tunes hyperparameters such as the learning rate and batch size, and utilizes various optimization algorithms to determine which model best suits a given job. Additionally, the expansion of LLM applications will include incorporating few-shot and zero-shot learning. This involves training a model with few or null examples of a target job. At the moment, few-shot learning is possible with GPT-3.
The process of developing LLMs is dynamic and characterized by ongoing investigation and improvement. Beyond only helping with language comprehension, LLMs are having a positive influence on the development of a smarter, more connected world.
Endless possibilities for creativity and exploration exist, and we are only getting started on this journey. LLMs will influence how we engage with information, one another, and the outside world through ethical deployment, responsible development, and ongoing study.
Additionally, hiring an AI developer make a significant impact on the direction of technology, and learning AI programming techniques is not only desirable but also necessary. A thorough grasp of AI programming not only helps developers to safely traverse the many facets of AI technology, but it also maintains the human-AI element and critical thinking that are essential for responsible AI development.
Sophisticated AI models, known as Big Language Models (LLMs), create and comprehend writing that resembles that of a human. 2024 will see them play a major part in several applications, such as content generation and natural language processing, which will completely change how we engage with technology.
Dissimilar to conventional language models, LLMs utilize extensive datasets and advanced architectures, allowing them to understand context, produce well-organized answers, and carry out intricate language-related tasks. More complex and human-like interactions are now possible because of this development.
Although the LLM market is changing, models like XLNet, BERT-XL, and GPT-4 are still at the top as of 2024. When it comes to activities like content creation, language translation, and text comprehension, these models excel.
Linguistic applications are not the only uses for LLMs. They have had a big impact on a lot of different businesses, like finance, healthcare, and the creation of original content. Their capacity to comprehend and analyze large volumes of information makes them invaluable resources in a variety of professional fields.
Even if LLMs have revolutionary potential, worries about bias, the spread of false information, and the application of AI technology still exist. The development of ethical AI practices, continued research, and cooperation between businesses, academia, and policymakers are necessary to address these problems.
Companies can use LLMs to improve customer service, automate processes, and extract valuable insights from large volumes of textual data. Innovative solutions, higher productivity, and enhanced efficiency can result from the integration of LLMs into applications and services in a variety of industries.














