16 Feb 2024
Table of Contents
It’s been widely discussed that this is the golden age of artificial intelligence (AI). Accordingly Satya Nadella, spoke in early 2023 with the World Economic Forum about the AI breakthroughs capturing global attention. Emphatically, “AI is just at the beginning of the S-curve,” the Microsoft Chairman and CEO says. “The near-term and long-term opportunities are enormous.”
Since late 2022 we’ve seen ongoing AI-powered launches, research, and advancements. Whether it’s the transformation of industries in work modes, services, or ongoing innovation and access, AI connects and unites everyone. And almost a year on from the pivotal launch of OpenAI’s ChatGPT-3.5, the AI advancement continues.
So as we begin the final quarter of 2023 and look ahead to 2025, what’s next in AI? In Nadella’s words, “a golden age of AI is under way and will redefine work as we know it”. Not only does this indicate that we’re still in the early days of transformation but also that advancement begets advancement.
In fact, post-September 2023 update announcements for ChatGPT-4, the next era promises the realization of multimodal AI.
Coupled with the ongoing AI developments of other powerhouse technology companies — Microsoft, Meta, Google, and Amazon — these advancements are colossal. In reality we’ve seen generative AI (GenAI) become functionally multimodal AI in less than 12 months. As per Grand View Research Report, the global large language model market size was estimated at USD 4.35 billion in 2023 and is projected to grow at a compound annual growth rate (CAGR) of 35.9% from 2024 to 2030. With milestone after milestone achieved, everyone is considering what is ahead for AI in 2025. Now we’ll dive into this expert guide on the next AI frontier and everything businesses should know about multimodal LLM.
Understanding the models of Artificial Intelligence
The best place to start with understanding multimodal LLM is reviewing training models common in AI products. Before we unpack the model and training definitions, businesses need to understand the overarching system that AI is.
The structure of AI and how these systems are engineered
IBM defines that, “The easiest way to think about artificial intelligence, machine learning, deep learning and neural networks is to think of them as a series of AI systems from largest to smallest, each encompassing the next.”
Generally speaking, AI is the broadest official term for this technology vertical and it functions as an overarching system. Then the following descend in the AI hierarchical system from there:
- Machine learning (ML) is a subset of AI
- Deep learning (DL) is an ML subfield
- Neural networks are the DL algorithmic pillars
Basically every AI needs to be data trained with large data sets. Afterwards, with inputs, the AI can have automated responses from rule-based, conversational, or generative capabilities. Indeed, in 1959, computer scientist Arthur Samuel refined the ML definition as, “computer’s ability to learn without being explicitly programmed”.
Key AI terminology
Machine Learning (ML)
The first level of the AI system is ML and it is a subset designed for optimization. “When set up correctly, it helps you make predictions that minimize the errors that arise from merely guessing,” explains IBM. Basically this helps machines — aka the AI — learn information and operations, identify patterns, undertake tasks, and accurately provide results.
When AI engages with human inputs, such as user prompts, the foundational programming managed through ML is leveraged. Large language models (LLM) are used for ML in order to train algorithms for prompts using human language and data.
The foundational models are trained for prompts from humans using ML techniques. Specifically algorithms are trained on natural language processing (NLP) and natural language generation (NLG) tasks ahead of market use. Though multimodal LLM training involves many dataset types, NLP and NLG enable AI responses to text and voice prompts.
There are different kinds of ML that make up this subset:
-Deep Learning (DL)
DL is a subset of ML. IBM explains that, “The primary difference between machine learning and deep learning is how each algorithm learns and how much data each type of algorithm uses.” Unlike ML, with DL there is considerable automation of the “feature extraction” ML process. Subsequently DL is sometimes called ‘scalable machine learning’.
Because automation allows computers to learn from large data sets without manual input, this results in unstructured data exploration. Presently many businesses don’t have structured data so this DL type enables sophisticated AI tasks such as fraud detection.
-Classic or Non-Deep Learning
Classic or Non-Deep ML depends on human intervention for the machine to undertake its activities. The human expert will actually determine the hierarchy of features to differentiate between data inputs.
-Reinforcement Learning
This ML category involves the computer learning through interaction and feedback. While interacting with its surroundings, the machine receives rewards or penalties with each activity.
-Online Learning
During this ML, a data scientist updates the model as data emerges or becomes available.
Neural Networks
This is another subset of ML. In general, these are called artificial neural networks (ANNs) or simulated neural networks (SNNs). Owing to the engineering structure, these neural networks create a DL algorithm’s backbone. IBM says, “They are called “neural” because they mimic how neurons in the brain signal one another.” In application, the neural network is the transformer architecture that processes input data from user prompts then performs NLP output.
The neural network’s structure consists of node layers that connect to each other with their own weight and threshold value. The node layer is: an input layer, one or multiple hidden layers, and an output layer. The nodes interact through the threshold layers passing data. When a node’s output is above its threshold value, it activates then sends data to the neural network’s next layer. If the threshold value isn’t reached then no data is sent along.
With ML, the training data teaches the neural networks and accuracy progressively improves with time. In time learning algorithms are fine-tuned then they become fast and accurate computer science and AI system building blocks. For instance, these ANNs and SNNs can recognize images and speech like the Google search algorithm neural network.
Supervised and Unsupervised Learning types
These two ML types help train AI. With both types, the data science approaches are intended to train machines to predict outcomes. Even so, supervised ML uses labeled datasets for training whereas unsupervised ML does not. Though this is the main difference between the two types, each has its place depending on situational needs.
Supervised ML learns through a labeled dataset that trains through iterative predictions and response-based adjustments. Overall these are slightly more accurate than unsupervised ML though human intervention is necessary.
Unsupervised ML autonomously explores unlabeled data to discover the inherent structure. Despite this, human intervention is still necessary to validate outcomes. Even if the outcome is accurate, data analysts still need to provide input to approve or disprove identifications.
There is also the option to use Semi-supervised learning that trains machines using both labeled and unlabeled datasets. In fact IBM emphasizes, “It’s particularly useful when it’s difficult to extract relevant features from data — and when you have a high volume of data.”
Data Sets
This is the literal data collection used for AI model training. When training happens then the data is organized for input so the model can learn recognition, classification, and make predictions.
The most common dataset types used for ML training modes are:
- Text data
- Audio data
- Video data
- Image data
It’s possible for AI using a multimodal LLM to understand prompts using these modes of text, audio, video, and images.
The technical structure and advantages of Multimodal LLM
To begin we’ll define what a multimodal LLM is. Then we can compare GenAI, conversational, and multimodal AI with references to the advancements in AI getting to this point.
How Multimodal LLM responds to user prompts
George Lawton writes for TechTarget that the multimodal LLM means the AI’s data types can work in tandem. According to Lawton, this advances how content is established and better interprets context. “Multimodal AI systems train with and use video, audio, speech, images, text and a range of traditional numerical data sets.” Undeniably this leads to more powerful and accurate AI functionalities that are integratable.
This data training diversification means that the model can learn from and process multiple models and data types. For example, OpenAI’s newest updates promise the extensive functionalities users can expect from ChatGPT-4’s multimodal LLM capabilities. OpenAI’s official announcement references these real-world applications as “ChatGPT can now see, hear, and speak”.
Undeniably the move towards multimodal LLM is not restricted to OpenAI’s developments. At present, leading AI companies including Microsoft, Google, Salesforce, and Amazon are working on their own multimodal LLM products. Google launched Gemini (formerly Bard) which is a groundbreaking innovation in the development of large language models. Moreover, the global NLP market, a central part of training multimodal LLM, is projected to quadruple between 2023 and 2030. Correspondingly, Statista finds that the market is worth USD$24 billion and it will exceed USD$112 billion by 2030.
Want to know about Google’s Latest Move on Its AI Model?
Why does Multimodal LLM advance existing AI products?
Before this, we’ve explained the structure of AI and basic ML to train the powering models. Hence here we’ll be talking about the ML datasets used for multimodal LLM training. Following training, the multimodal LLM can use its language reasoning skills for the image, auditory, and text prompts. For instance, this is why ChatGPT-4 can now use voice input to generate original images. Comparatively Google Cloud’s Kaz Sato and Ivan Cheung attest how a vision language model (VLM) has the “ability to understand the meaning of images”. Both examples show this burgeoning AI niche’s dynamic reach and potential as effectively mixing datatype multimodal models is achieved.
Further to our training explanation, we need to take a practical outlook that addresses the text-only LLM limitations. “Language models have only been trained on text, making them inconsistent on tasks that require common sense and basic world knowledge,” contends Ben Dickson for TechTalks. Consequently, this helps explain the intelligence advancements coming for the existing text-based LLM powering generative AI like ChatGPT. And, ultimately this expands the horizon of AI technology as we know it while promising a new phase of innovation.
How Multimodal LLM training happens for the different data modes
1. Text data training
Text data training uses text and NLP datasets to help machines learning modes of human communication, speech, and language.
2. Voice data training
Voice recognition data training uses vocal and spoken inputs to recognize speech patterns, speech sounds, and language use.
3. Image and video data training
Vision training uses visual data, namely images and videos, to train machines to process, interpret, and derive information like humans.
Since multimodal LLM is becoming so accurate it shows that computer vision, on the pixel level, is akin to humans. Thus these text, voice, image, and video capabilities will equip AI to process prompts and deliver more reliable output.
How GenAI and Multimodal LLM AI capabilities differ
To sum up the differences, the fact is that multimodal LLM developments are the next advancement in GenAI. Because conversational AI advancements realized with ChatGPT demonstrated that reliable generative AI was achievable, multimodal LLM raises the bar again. Moreover, ChatGPT-4 updates announced in late August and September 2023 are consistent with other AI research developments. For example, Microsoft’s Bing Chat multimodal visual search was announced before OpenAI’s in July 2023.
GenAI current capabilities
- Built on Large Language Models (LLM) — most likely text-based
- Respond to prompts with responses and generative output based on foundation model data training — usually text but some types can respond to multimodal prompts though unimodal models take only one input type
- Identify issues with writing and code
- Personalization for users supporting conversational user experience (UX)
- Potential for inaccuracies based on training model data and some bias and “hallucinations” recorded.
How Multimodal LLM advances GenAI
- Responds to image, voice, and video prompts to create the same or different output such as voice prompt to original image output
- Multimodal processing algorithms can undertake the processing of differing modalities simultaneously for higher performance that approaches human processing and intelligence
- More robust, fast, accurate, and dynamic output
- Potential to be more accurate as datasets are more refined and can access the open web. Equally, there is a risk for ‘dirty’ data sources as open web access is normalized across models.
Stay Ahead in The Game and Integrate Future-ready AI-powered Solutions in your Business
Connect with us
Why Multimodal LLM technology advances conversational AI and GenAI chatbots
Undoubtedly it was a historic moment when GenAI was heralded as the most advanced chatbot ever in late 2022. On account of the generative conversational capabilities, it was an exciting example of the AI functionalities long promised in technology. Now at the dawn of multimodal LLM, the AI is diversifying again and we enter a new age of chatbots.
Five groundbreaking changes to chatbots using Multimodal LLM AI
- An actual virtual assistant that can interact on multiple different modes depending on user preference and languages, for example accurate voice recognition and translation
- Provides 360-degree feedback that’s comparable to fictionalized movie AI because users can request an image mockup from a voicenote
- Analyzes live data from the open web to provide critical insights and advice
- Offers a true ‘handsfree’ UX in a range of scenarios using images and video, voice, and text input
- Enhanced personalization for customers with live resolutions using real-world input such as interpreting photos of product issues.
Leading Multimodal LLM AI products
Unquestionably there is considerable attention on OpenAI — and now multimodal LLM AI — in the GenAI space. Despite this, OpenAI’s ChatGPT-4 updates put them alongside fellow technology companies who already have multimodal LLM products. Nevertheless, due to OpenAI’s partially open-source research laboratory most advancements help the market maintain progress.
Examples of leading technology company’’s Multimodal LLM AI models and products
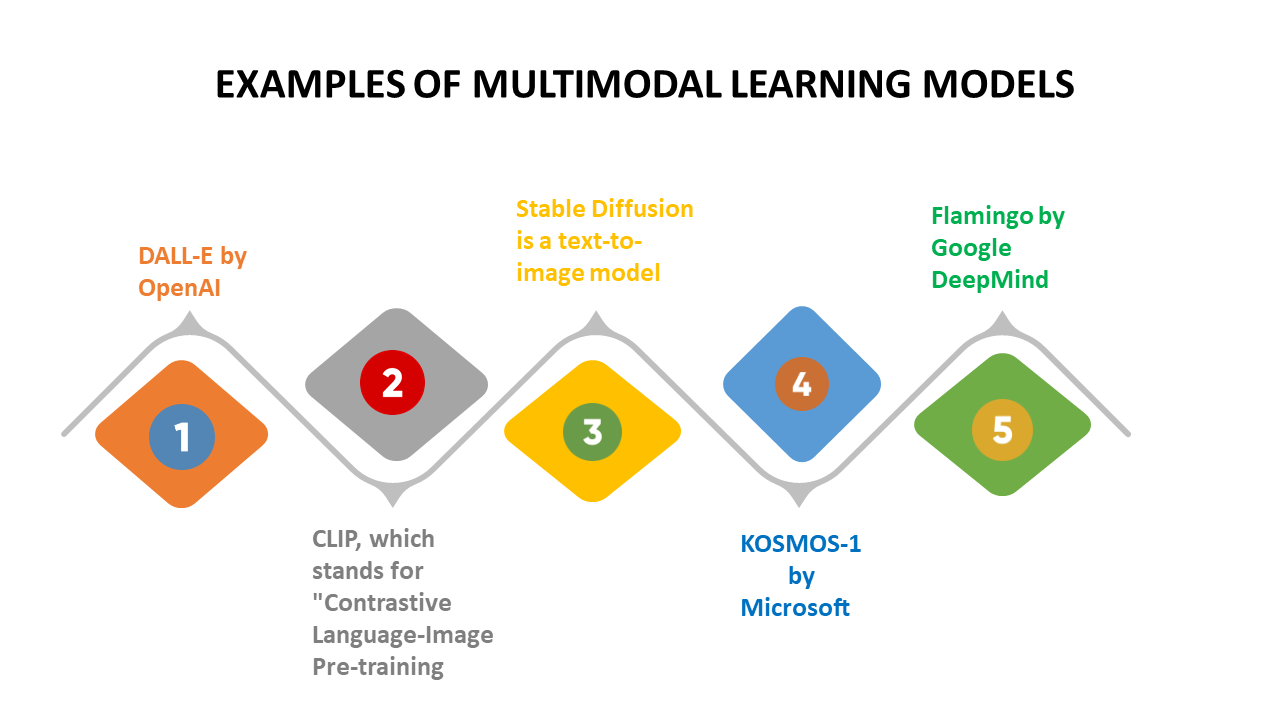
OpenAI
The OpenAI move towards functional multimodal AI is obvious with their ChatGPT 4.0 product. While ChatGPT 3.5 marked a turning point in GenAI, the 4.0 product handles text, image, and voice inputs. OpenAI’s DALL-E 3 model can now simultaneously take text and translate it to original image output. Thus ChatGPT 4 is truly multimodal as well as now having access to internet browsing.
Stability AI
Altogether this is a disruptive force in open AI development. Certainly, their multimodal AI potential is obvious through their Stable Audio model, Stable Diffusion XL image model, and Language models. Accordingly, Siddharth Jindal explains, “Stability AI possesses all the necessary resources to craft an open-source multimodal model.” Presently it’s unclear when this will realized. Nonetheless, an open-source multimodal LLM will be especially groundbreaking for this AI niche.
Another multimodal AI release on the horizon is Google’s Gemini which will reportedly be able to process multiple data inputs. Early announcements suggest competitive features like handling text and images to provide analysis and output such as graph reading. At present Google is still testing and fine-tuning their Gemini multimodal LLM model. Some early testing also speculates that the Gemini model will be more powerful than ChatGPT because it leverages Google data.
Meta
Meta (previously Facebook) is at work on numerous multimodal AI LLM through MetaAI. Firstly, the newly released ImageBind can bind data from six modalities at once without the need for explicit supervision. These modalities are image, audio, and text that bind together to create a sensory UX. Hence this gives the computer vision as ImageBind recognizes the relationships between the modalities.
Simultaneously the multimodal LLM SeamlessM4T is now also available. The translation AI can handle speech and text input to accurately translate up to 100 input languages. Due to the multimodal LLM functionalities, Meta asserts the single system will advance universal language translation. SeamlessM4T can handle varying speech-to-speech, speech-to-text, text-to-text, and text-to-speech functionalities.
Amazon
Currently, Amazon hasn’t announced any official LLM products. Nevertheless, demos of a high-quality multimodal Alexa LLM are circulating. Following a glimpse on an Amazon blog, it’s expected that Alexa will have new multimodal capabilities surpassing voice mode soon.
Apple
All things considered, Apple’s place in the generative AI and multimodal AI space remains to be seen. According to investigations, Apple is spending millions on its AI developments. Furthermore, its Ajax GPT has reportedly been trained on a powerful LLM of more than 200 billion parameters. This is a “watch this space” scenario though many speculate that Siri 2.0 will be multimodal LLM-enabled.
Explore Innovative Solutions For Your Business In This New Age of AI
What’s next for LLM training as Multimodal AI moves online
Markedly the mainstreaming of multimodal LLM AI technology coincides with OpenAI announcing ChatGPT-4 will soon have open web accessibility. So, what does this mean for users, businesses, and the global community as AI continues to evolve and become normalized?
On the positive side, as ChatGPT’s training was on datasets up to September 2021 this removes the source timeline cap. This promises opportunities for greater accuracy and there will be references to the chatbot’s own technological impact. On the negative side, though ChatGPT — and most leading AI models — are trained on massive datasets, quantity isn’t necessarily quality. For instance, the open web creates arguably exponential data sources that may be neither accurate nor up to informational standards.
There’s a considerable risk of misinformation, inaccuracies, misrepresentation, and simple information overload leading to a poor UX among other negative outcomes. In this case, time will tell how open web access affects both ChatGPT’s accuracy and its source quality. Further to this, it may cause another epoch in digital information verification, sharing, and quality standards across all technological forms.
Why businesses must risk managing their AI system and technology at all times
It’s non-negotiable that all businesses — and anyone using AI — thoroughly grasp these concepts to protect stakeholders. Because AI systems and systems integrated with AI handle a range of private individual and collective data technology quality matters. There are risks to customer privacy, data rights, and macro and micro trust. When businesses compromise any of these stakeholder points of interest — including for their employees — damages can be extensive and disastrous. Rather than take any risks in these areas, the same precautions with cybersecurity, data privacy, and compliance are essential actions.
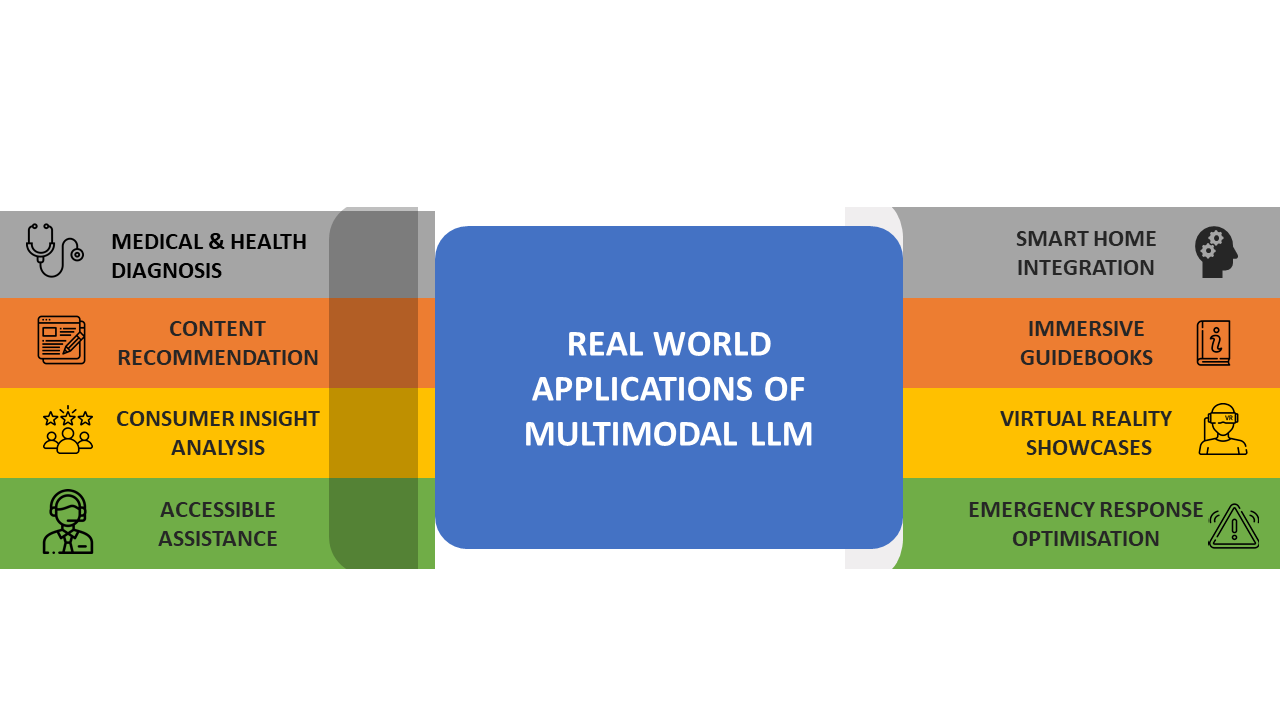
Nine world-changing case studies and transformations that Multimodal LLM AI is leveling up
All in all the advent of the multimodal LLM realizes a highly exciting new AI paradigm. In this final section, we’ll review nine case studies of early use that suggest further innovations we can expect.
9 Applications of Multimodal LLM
1. Prosthetics
Physical limitations will be overcome as AI is integrated into prosthetic limbs. This can help with controlling limbs, interpreting nerve signals through implants, and making sensory feedback a reality. Modal functionalities like computer vision mean wearers could have prosthetic limbs that can move without manual intervention.
2. Medical and health data
The next generation of AI will have a pivotal impact on how medical and health data is analyzed. For instance non-verbal patients can communicate with doctors or AI can process multimodal patient results like brain scans and blood tests. Not only does multimodal LLM AI support diagnosis and accuracy but also they help advance medical research and health understanding.
3. Accessibility
Accessibility is already a major advancement multimodal LLM AI delivers. For example, OpenAI explains working with Be My Eyes a free mobile service for blind and low-vision people. In that case, vision input to the multimodal LLM prompts the AI to conversationally describe images on TV. When multimodal LLM is part of AI, this creates technology that can better support users needing dynamic accessibility tools.
4. Metaverse
The varied modal inputs a multimodal LLM can handle are a fundamental part of developing a functional Metaverse. The multimodal inputs of image, text, and voice improve the augmented reality (AR) and virtual reality (VR) UX. Seamless multimodal integration delivers a more lifelike and natural UX that properly immerses users with more accurate ML than unimodal.
5. Multilingual communication
Designing products with multimodal LLM AI functionalities is already happening as with the Meta SeamlessM4T model that’s just launched. Until now, translation ML was already quite functional however Meta’s model enhances both UX and ML understanding of multimodal inputs.
6. Financial analysis
Using a robust Multimodal LLM, the finance industry can transform several areas. Whether analyzing records for risk management and trends or fraud detection for auditing, multimodal LLM processes various data modes. Because the volume and complexity of data are significant, this makes the promise of accuracy even more appealing.
7. Education
Multimodal LLM technology supports student outcomes across formal and informal learning settings. In summary, the multimodal prompts and outputs support different learning styles, accessibility, immersive and 360-degree learning. This is beneficial for learners across schools and training, those needing educational aid, and varied socio-economic and cultural spheres.
8. Retail
Taking customer experience (CX) to the next level happens through multimodal LLM in all areas of retail. Particularly for personalization, stock management, and predicting purchasing, this streamlines retail processes. What’s more, this supports sustainability efforts to reduce unnecessary production while also improving goods in real time following customer feedback.
9. Machinery
Besides the technological advancements of using brain implants for controlling machinery, multimodal LLM AI progresses driverless cars and unpiloted planes. Despite the promise of Elon Musk’s Neuralink, multimodal AI bypasses surgery-dependent brain implants while still delivering functional outcomes. With computer vision capabilities, automatic machinery can be faster, safer, and more accurate.
Conclusion
Though GlobeNewswire reports the AI industry’s current worth is $150.2 billion, the best approach for all businesses is strategic investment. After all, as we’ve covered in this guide, growth is progressing at an exponential scale. Although the future is unknown this is only the beginning of AI and multimodal LLM.
On the one hand, GlobeNewswire analysis finds that the AI market is propelled through “synergistic interaction with various other technologies”. They assert, “Moreover, the growth of cloud computing infrastructure and the availability of AI-as-a-Service platforms make artificial intelligence more accessible to businesses of all sizes, facilitating rapid adoption and implementation.”
On the other hand, the technology itself will keep informing its progress as it continues upwards with rapid advances. Because the AI has an awareness of all parts of itself its potency will only grow as it evolves. Thereafter we’ll reflect on this time as the infancy of AI with its compounding development continuing at an extraordinary rate.
In conclusion, businesses ready to integrate AI-powered solutions are best positioned when they engage in professional software consultation. Because expert insights equip them to make informed, roadmap-based decisions then working with experienced AI developers is endlessly beneficial. Furthermore, IBM asserts that “Your AI must be explainable, fair, and transparent.” Hence working with knowledgeable professionals is crucial to bringing trustworthy, safe, security-centric, and robust systems to life.
Get started on the journey towards ethical, AI-integrated software
Contact A3Logics today for a preliminary business consultation
Frequently Asked Questions (FAQs)
What is a Multimodal Large Language Model (LLM)?
A multimodal LLM is a subset of AI. It can also be considered a niche of AI comparable to the preceding niche of Generative AI (GenAI).
In essence, a multimodal LLM is an AI system trained with multiple modes of data. For instance, existing multimodal LLM are trained on image, text, and audio data.
Is a Multimodal LLM better than Generative AI?
Overall it is difficult to argue that one subset of AI is superior to another. To illustrate, it’s most important to differentiate between these subsets:
GenAI
- LLM trained — most likely text training
- Responds to unimodal — often text — prompts
- Analyzes issues with prompts or generates original responses to prompts
- Offers personalized UX
- Training may be limited to machine learning data sets
Multimodal LLM AI
- Has the same features as GenAI
- Trained with additional modes — text, image, and audio
- May have a wider training data set such as online sources
- Multimodal prompts can result in multimodal responses
When we consider the current AI landscape, both AI subsets have their value. Basically, all AI subsets are valuable as they enable dynamic system functionalities.
What businesses benefit from using Multimodal LLM AI?
All businesses can benefit from using a multimodal LLM AI. Due to the scope and range of functionalities, multimodal AI can be utilized in countless industries. For example, multimodal AI is already being used in education, healthcare, and communications. Furthermore, multimodal LLM AI will be integratable with hardware and software thus expanding its potential uses again.
Will the OpenAI Multimodal LLM be free for businesses to integrate?
At present OpenAI has announced its multimodal LLM use in ChatGPT-4. Nevertheless, certain multimodal functionalities of the OpenAI LLM are not available in free ChatGPT products. Therefore businesses need to understand the dynamic functionalities of the model as they begin planning integrating the AI.
To do this, businesses can start with a generative AI development company consultation to evaluate their needs. Experienced developers of A3Logics support businesses in understanding the difference between paid and enterprise OpenAI products. Then they’ll recommend solution design, what’s currently available, and how to decide on an AI investment.
Table of Contents

Abhinav Choudhary
Abhinav Choudhary is a dynamic Data Analytics Manager who excels in streamlining workflows and ensuring seamless execution. He focuses on efficiency and quality and delivers projects that meet client expectations and drive business success.




