Table of Contents
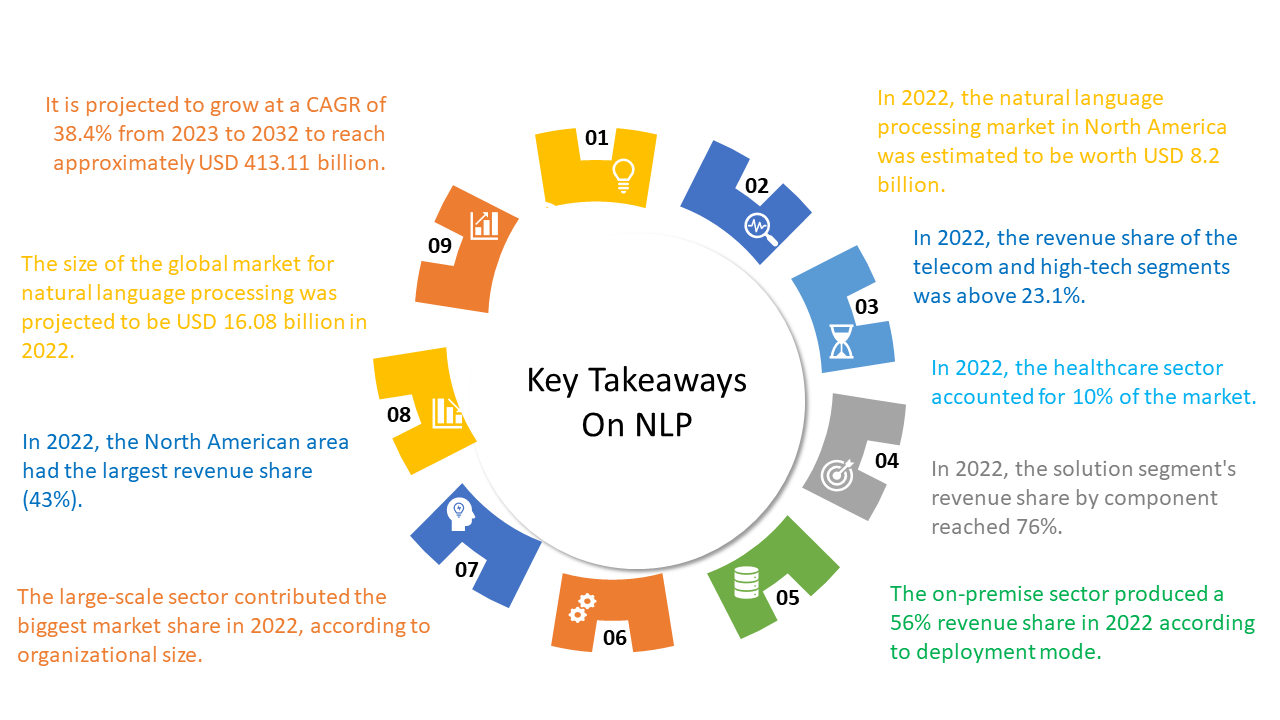
In the constantly evolving landscape of language innovation, the analysis between NLP v/s LLM has become huge. The market analysis by Markets and Markets predicts that the use of NLP will increase from $11.6 billion in 2020 to $35.1 billion by 2026. The extensive variety of NLP applications can revolutionize different industries, enabling them to upgrade their products, and services by integrating human languages and innovation.
NLP, a subfield of artificial intelligence, focuses on enabling machines to understand, interpret, and create human-like language. Then again, a Large language model development company, presented by extraordinary models like GPT-3, stands out for its momentous language generation abilities.
With NLP being a laid-out player and LLM emerging as a revolutionizing power, navigating the distinctions between the two is critical. Furthermore, this introduction aims to unwind the intricacies of NLP and LLM, providing insights into their functionalities, applications, and the most recent headways that drive their prominence in language innovation.
A Brief Overview
A large language model (LLM) is a deep learning calculation that can play out a diversity of natural language processing (NLP) tasks. Large language models use transformer models and are trained using huge datasets — subsequently, large. Moreover, this empowers them to perceive, and decode, predict, or create text or other objects.
Large language models are additionally referred to as Neural Networks (NNs), which are computing frameworks inspired by the human brain. Overall, these brain networks work using an organization of hubs that are layered, similar to neurons.
As well as training human languages for artificial intelligence applications, large language models can likewise be trained to play out various projects like understanding structures, writing programming code, etc.
Like the human brain, large language models should be pre-trained and then, at that point, fine-tuned so they can tackle text structure, question answering, archive synopsis, and text generation. Their problem-solving capacities can be applied to fields like medical care, finance, and entertainment. This is where large language models serve a mix of NLP services, like interpretation, chatbots, AI collaborators, and so on.
What is NLP?
Natural Language Processing technology is a part of artificial intelligence (AI) that arranges with training machines to understand, process, and create language. Web search tools, machine interpretation services, and voice assistants are controlled by creativity and invention in technology.
While the term originally refers to a framework’s capacity to read, it’s since turned into an expression for all computational language. Moreover, subcategories comprise natural language understanding (NLU), which is the ability of a machine to comprehend misspellings, shoptalk, and other linguistic variances, and natural language generation (NLG), which is a PC’s ability to communicate on its own.
The introduction of transformer models in the 2017 paper “Attention Is All You Need” by Google researchers revolutionized NLP, leading to the production of generative AI tools. Like for example, bidirectional encoder representations from Transformer (BERT) and ensuing DistilBERT — a more modest, quicker, and more proficient BERT — Generative Pre-trained Transformer (GPT), and Google Bard (Now Gemini).
Key Techniques Used in Natural Language Processing
Natural Language Processing (NLP) stands as a multifaceted domain, demanding the capable utilization of different strategies to investigate and understand human language successfully.
In the following discussion, we dig into an investigation and clarification of a different group of strategies that find typical use in the domain of NLP innovation, solving the complex embroidery that underlies the consistent processing of linguistic data. According to AI statistics, the demand for NLP technologies is rapidly growing, driving advancements in language processing and automation.
1. Tokenization
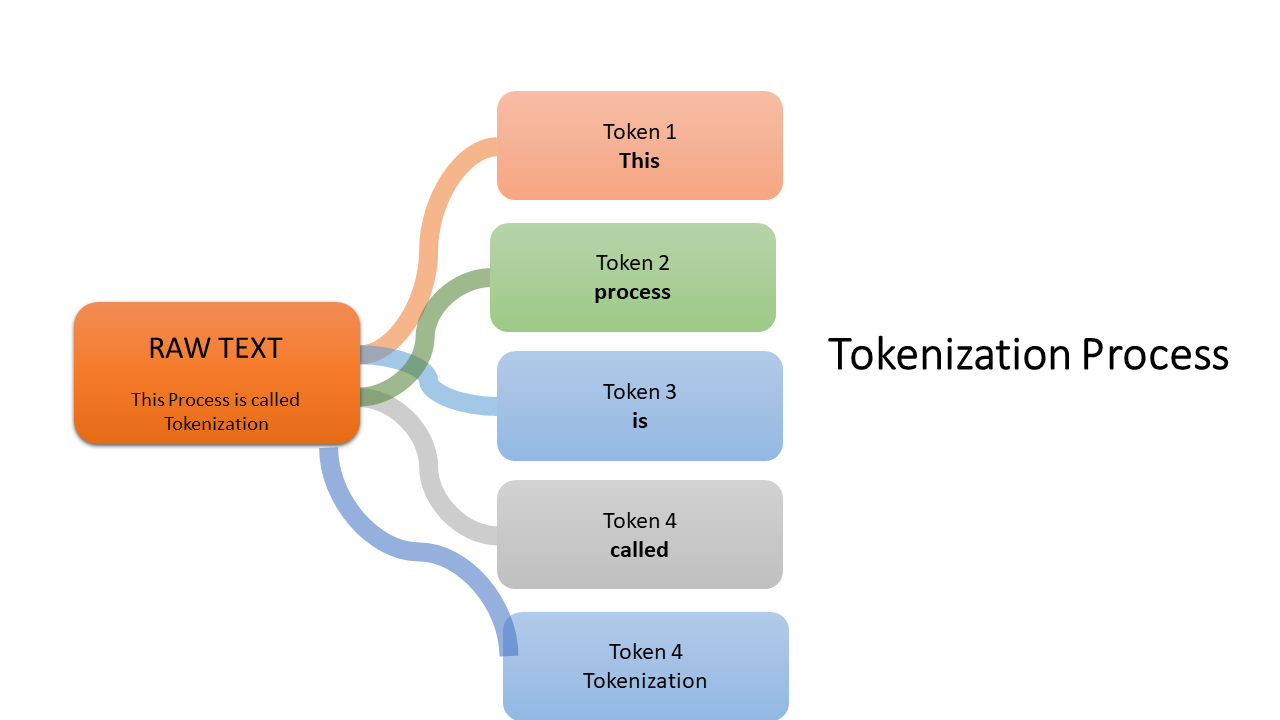
Tokenization, likewise referred to as word division, stands out as a principal and indispensable procedure within the extensive domain of Natural Language Processing (NLP). Overall, serving as a vital preprocessing step, its importance lies in the intricate process of dissecting extended strings of text into additional reasonable and meaningful units, suitably named tokens.
Furthermore, this extraordinary procedure involves the analysis of a continuous string of text into more modest components. Wherein the resulting tokens include a range ranging from whole words and characters to more fine sub-words.
Functioning as the essential building block of NLP, tokens play a central job in facilitating the consistent digestion and perception of natural language by computational models. In the fine landscape of NLP innovation, the tokenization process expects vital significance, as it provides an organized structure for ensuing investigations and interpretations.
Furthermore, by breaking down linguistic input into noticeable units, NLP models gain the capacity to work on a more fine level, navigating through the complexities of language with upgraded accuracy and context-oriented mindfulness.
Thus, the Tokenization process turns into a backbone in the viability of NLP models, contributing essentially to the achievement and exactness of ensuing natural language processing tasks.
2. Morphological segmentation
Morphological division, an essential part of linguistic investigation, intricately involves the careful analysis of words into their constituent morphemes — the natural units of language that epitomize meaning.
Moreover, in the intricate artwork of linguistic construction, morphemes act as fundamental building blocks, carrying subtle semantic importance. Outstandingly, certain words, for example, “table” and “lamp,” remain monomorphemic, comprising a single morpheme that conveys their intended meaning with singular lucidity.
Nonetheless, the linguistic landscape turns out to be more intricate with words that epitomize multiple morphemes. Overall, an outstanding representation of this intricacy is tracked down in “Sunrise,” which contains two distinct morphemes: “sun” and “rise.”
This peculiarity epitomizes the multifaceted idea of language, where the combination of morphemes adds to the all-encompassing understanding of word meanings.

3. Stop word removal
In the multifaceted landscape of Natural Language Processing (NLP), the elimination of stop words arises as a critical pre-processing step, decisively intended to remove extra-linguistic details that contribute practically nothing to the considerable meaning of a text.
Stop words envelop a range of linguistic components, ranging from normal conjunctions like “and” and “because” to pervasive relational words, for example, “under” and “in.”
The reasoning behind this particular evacuation of stop words lies in optimizing the focal point of Artificial Intelligence (AI) frameworks. Furthermore, by exercising these filler words, NLP models can focus their cognitive resources on the linguistic components that convey inherent semantic importance.
Thus, the resultant dataset turns out to be more streamlined and minimized, paving the way for upgraded productivity in processing.

4. Text classification
Text classification fills in as an encyclopedic term containing different methods intended to methodically coordinate tremendous amounts of unprocessed printed data. Furthermore, among its various applications are opinion investigation, point modeling, and watchword extraction, each contributing to distinct aspects of the collection process.
At its center, text order involves the change of unstructured text data into an organized configuration, consequently facilitating the following investigations. Overall, this flexible approach is pertinent across a wide range of print settings, offering support for various hierarchical and order tasks.
Indeed, message order assumes an urgent part of the domain of Natural Language Processing (NLP), proving indispensable in different applications, ranging from the ID of spam to the monitoring of brand sentiments.
Its utility stretches out to a heap of situations, where it aids in enhancing hierarchical proficiency and promoting a subtle understanding of text-based content.
A few important utilizations of text characterization include:
- Categorizing product surveys gives a feeling to streamline customer insights.
- Prioritizing client emails by flagging them as pretty much critical for productive reactions across the board.
- Structuring content by theme, facilitating consistent route and recovery of information.
Fundamentally, text order stands as a foundation in the store of NLP devices, playing an essential job in transforming disorganized academic data into a significant resource for informed navigation and insightful study.
5. Sentiment analysis
Sentiment analysis technology, on the other hand, implied to be emotional AI or opinion mining, involves scrutinizing text-based content to recognize its overarching personal tone, categorizing it as one or the other good, pessimistic, or impartial.
Functioning as a significant procedure within the domain of Natural Language Processing (NLP) for message order, opinion analysis finds far and wide applications in different settings, with one prominent use being the examination of user-created content.
Overall, its versatility reaches out to different text classifications, encompassing audits, remarks, tweets, and articles.
6. Topic modeling
Topic modeling stands as a strategy that deliberately examines reports to uncover underlying topics and examples of large language models capably clustering interconnected presentations and word groupings to dole out meaningful labels to the dataset.
This method works as a solo machine learning process, signifying its capacity to explore through unstructured data without the essential of an earlier order by human annotators.
Fundamentally, it independently recognizes and arranges subjects within the corpus, showcasing its effectiveness in discerning latent designs and connections within printed content.
6. Keyword extraction
Keyword extraction stands as a strategic approach that filters through a report, discarding pointless filler words, and pinpointing the core of importance implanted in fundamental watchwords.
Its basic role lies in the computerized extraction of significant words and expressions most often utilized within a record, subsequently facilitating the making of concise summaries and explaining the central topic.
This strategy proves especially worthwhile in different situations where the objective is pinpointing a subject of interest within a text-based dataset.
For instance, it proves invaluable in discerning repetitive issues in client emails, offering a streamlined method for identifying and understanding predominant problems that reliably emerge.
7. Text summarization
This specific NLP strategy succeeds in condensing text-based content into a strong outline, proving invaluable for the extraction of relevant information from a given source.
Furthermore, dissimilar to the tedious process that a human would go through to carefully read a whole report for a precise synopsis, a programmed text rundown accomplishes this project with a striking rate.
8. Parsing
Parsing entails the complex process of examining the sentence’s grammatical structure, identifying the precise relationships between words to differentiate between forms, and figuring out whether words function as the subject or object of an action word.
Overall, in the domain of Natural Language Processing (NLP), parsing fills in as an essential method, furnishing supporting logical insights to work with the exact processing and analysis of literary data.
9. Named Entity Recognition
Named Entity Recognition (NER) is a form of information extraction that identifies and labels “named entities” using predefined keywords, such as names, locations, dates, events, and more.
Beyond merely tagging a document with keywords, NER also tracks the frequency of mentions for each named entity within a specific dataset. NER bears similarities to keyword extraction, but the extracted keywords are organized into predefined categories.
Furthermore, this technique proves valuable in determining how frequently a particular term or topic appears in a given dataset. For instance, NER could be applied to discern that a specific issue, designated by words like “slow” or “expensive,” recurs consistently in customer reviews.
10. TF-IDF
TF-IDF, an acronym for the term frequency-inverse document frequency, is a statistical methodology used to assess the significance of a word within a specific document relative to a collection of documents.
This technique relies on two key metrics: the frequency of a word’s occurrence in a given document and the frequency of the same word across the entire set of documents.
When a word is pervasive across all documents, it receives a lower score, even if its occurrence is frequent. Conversely, if a word is prominently featured in a single document while being irregular in the remaining documents of the set, it attains a higher ranking.
Overall, this high ranking suggests that the word holds significant relevance to that particular document.
Harness The Power of NLP in Your Business
Applications of NLP solutions
Natural Language Processing solutions have seen boundless reception across different industries because of their capacity to interpret and create human-like language. The following are seven applications that feature the various and significant uses of NLP:
1. Sentiment Analysis:
NLP is utilized to examine and understand the opinion communicated in literary data, for example, client audits, virtual entertainment remarks, or review reactions. Overall, this application assists businesses with gauging popular opinion, consumer loyalty, and brand understanding.
2. Chatbots and Virtual Assistants:
NLP controls the conversational interfaces of chatbots and remote helpers, allowing them to understand user questions and answers in a natural language design. Furthermore, this application improves client service, streamlining interactions and providing instant help.
3. Language Translation:
NLP is instrumental in language interpretation applications, enabling the precise change of text starting with one language and then onto the next. Overall, this innovation is crucial for worldwide communication, breaking down language obstructions continuously.
4. Information Extraction:
NLP can release applicable information from unstructured text, transforming it into organized data. Furthermore, his application is invaluable for processing large volumes of data, extracting key insights, and facilitating data-driven navigation.
5. Text Summarization:
NLP algorithms are used to investigate and gather extensive bits of the message into concise summaries while retaining the fundamental information. This application is urgent for rapidly extracting central issues from large archives, articles, or reports.
6. Named Entity Recognition (NER):
NLP methods are utilized in NER to recognize and characterize substances like names, areas, organizations, and dates within the text. This application is crucial in information recovery, content order, and data structuring.
7. Healthcare Information Extraction:
NLP assumes a vital part in extracting significant information from clinical records, clinical notes, and exploration papers. This application helps medical services professionals in productively analyzing patient data, improving diagnostics, and enhancing by and large understanding consideration.
The adaptability of NLP solutions continues to expand, with ongoing progressions contributing to their adequacy in addressing different difficulties and optimizing processes across industries. From enhancing client encounters to facilitating data analysis, NLP remains a foundation for the improvement of intelligent and language-minded applications.
Understanding Large Language Models
Large Language Models (LLMs) are refined artificial intelligence service frameworks intended to understand and create human language.
These frameworks are intended to get familiar with the examples, designs, and connections within a given human language and use them for different restricted AI tasks like text interpretation and text generation. This permits them to create new bliss, for example, papers or articles, that are comparable in style to a specific writer or kind.
Large language models depend on brain network structures that contain a colossal number of boundaries that permit them to process and interpret large measures of text data. The nature of a language model shifts enormously, depending mainly on its size, how much data it was trained on, and the intricacy of the learning algorithms used during training.
So how do multimodal LLMs work? So, it is a two-step process
- To start with, they go through pre-training, where they learn linguistic examples, sentence structure, and logical connections from a variety of message sources. This stage provides them with a fundamental understanding of the language.
- Then, the models are fine-tuned to explicit projects using smaller datasets, refining their presentation in tasks like interpretation, outline, and question answering. LLMs certainly stand out for their capacity to produce lucid and logically pertinent text, making them significant in different applications across industries.
Dive Into the World of Language Models and explore how our services can drive results
Core Technologies Used in LLM Solutions
Like some other programs, the power between language models is derived from their underlying advancements. Thus, they gain the capacity to oversee intricate language tasks with another level of refinement.
-
Deep Learning:
At the core of LLMs lies a subset of machine learning innovation that uses brain networks with many layers. These LLM development companies can learn and make intelligent choices all alone.
-
Transformers Architecture:
Numerous LLMs use a transformer model, appropriate for processing data successions. They empower the model to precisely foresee the following word in a sentence.
-
Self-Attention Tools:
The model measures the significance of various words in a sentence. This component helps in understanding the setting and generating pertinent reactions.
-
Versatility:
LLMs can be trained with increasing data to upgrade their presentation and capacities.
Applications for LLM Development Services
1. Using Language Models for Translation
Translating printed reports is one of the most straightforward and common uses for LLMs. At the point when a user enters text into a chatbot and demands an interpretation into an alternate language, the chatbot will initiate the interpretation process naturally.
According to some studies, LLMs like GPT-4 beat business interpretation services like Google Decode. Nonetheless, specialists additionally point out that GPT-4 performs best while translating European languages; it is less exact while translating “far off” or “low-resource” languages.
2. Content Creation – Text, Images, and Videos
The generation of content is another increasingly famous use case for language models. With LLMS, users might make a collection of composed material, like articles, websites, outlines, scripts, surveys, tests, and virtual entertainment postings. The information in the original prompt determines how well these results end up.
LLMs can be used to aid with ideation on the off chance that they aren’t used to straightforwardly making material. HubSpot reports that 33% of advertisers that utilize AI do so to develop ideas or wellsprings of inspiration for marketing material.
The essential advantage here is that artificial intelligence might assist in the making of content. Users are tasked with creating visual designs using software such as DALL-E, MidJourney, and Stable Diffusion based on textual instructions.
2. Search
As an elective inquiry device, generative AI will have initially been attempted by countless people. Clients might ask a chatbot for natural language inquiries, and it can answer instantly with information and analysis on practically any subject.
Even though you might get a ton of data by using search tools like Bard or ChatGPT solutions, you ought to be mindful that not all the material is solid.
Language models habitually make realities and numbers out of nowhere and are prone to hallucinations. In this way, in a request to forestall being tricked by bogus information, customers should affirm any exact information provided by LLMs.
3. Customer Service and Virtual Assistants
As remote helpers, generative AI experts appear to have promise in the field of client support.
According to a McKinsey study, the use of AI by a generative AI development company abbreviated issue-handling times by 9% and improved issue goals by 14% each hour at a firm with 5,000 client care representatives.
Clients may quickly enroll in concerns, look for discounts, and get information about services and products through AI remote helpers. It saves staff time via automating gloomy help procedures, and it eases end clients from having to wait for a human help delegate.
4. Cyberattack Detection and Prevention
Detecting cyberattacks is an extra intriguing online protection use case for language models. This is because of the way that LLMs can examine gigantic data sets assembled from a few sources inside a corporate organization, recognize designs that point to a cranky cyberattack, and then, at that point, raise a caution.
Various AI solution providers have up to this point begun experimenting with identification innovation. SentinelOne, for instance, disclosed an LLM-driven arrangement toward the beginning of the year that can consequently distinguish dangers and launch robotized responses to malignant activities.
Another technique, shown by Microsoft Security Copilot, empowers users to rapidly produce writes about conceivable security occasions and output their surroundings for known weaknesses and exploits, thus preparing human protectors for activity.
Comparing NLP and LLM: How to Differentiate the Two?
| ASPECT | Natural Language Processing | Large Language Model |
|---|---|---|
| Definition | NLP focuses on understanding and processing human language, enabling computers to interact with and interpret the text. | LLM, exemplified by models like GPT-3, goes beyond understanding to generate human-like text, exhibiting advanced language generation capabilities. |
| Scope | Primarily concerned with language comprehension, information extraction, and sentiment analysis. | Extends beyond comprehension to generate coherent and contextually relevant text, making it capable of creative language generation. |
| Training Data | Trained on specific datasets tailored to the application, often requiring labeled data for supervised learning. | Trained on massive and diverse datasets, learning patterns, and structures from a wide range of sources without task-specific data. |
| Applications | Commonly used in chatbots, sentiment analysis, language translation, and information extraction. | Applied in creative writing, content creation, language translation, and various other tasks that demand advanced language generation capabilities. |
| Task Complexity | Effective for specific, well-defined tasks such as sentiment analysis, language translation, and chatbots. | Exhibits versatility and excels in a wide range of tasks, from content creation to complex language understanding, making it a general-purpose language model. |
| Fine-tuning | Requires fine-tuning for specific tasks and domains to enhance performance. | Exhibits transfer learning capabilities, reducing the need for extensive fine-tuning, as the model already possesses a broad understanding of language. |
| Resource intensiveness | Generally requires fewer computational resources compared to large-scale language models. | Demand significant computational power and resources due to the massive scale of the model and training data. |
While NLP is more task-specific and focused on perception, LLM, especially presented by models like GPT-3, stands out for its more extensive language generation capacities and adaptability across different tasks.
Using NLP and LLM for Stellar Results
1. Understanding Explicit Business Needs:
– Recognize particular tasks or difficulties where NLP can bring esteem, like client sentiment analysis, content rundown, or chatbot execution.
2. Select the Right NLP Framework:
– Pick a reasonable NLP structure given your project requirements. Well-known frameworks include NLTK, SpaCy, and TensorFlow, each offering exceptional features and capacities.
3. Preprocess Data Effectively:
– Guarantee proper preprocessing of text-based data by cleaning, tokenizing, and normalizing the text. This step is critical to improve the exactness and adequacy of NLP models.
4. Optimize Model Selection:
– Select an appropriate NLP model in light of the intricacy of the task. Models like BERT and GPT-2 might be reasonable for intricate language understanding, while more straightforward models could get the job done for fundamental applications.
5. Fine-tuning for Domain-Explicit Tasks:
– Fine-tune pre-trained models with domain-explicit data to upgrade their exhibition on assignments applicable to your business. This step guarantees that the model adjusts well to your particular necessities.
6. Evaluate and Iterate:
– Consistently assess model execution using significant measurements. Repeat and refine the model given criticism and changing business requirements to maintain ideal outcomes.
Leveraging LLM for Exceptional Outcomes
1. Define Clear Objectives:
– Define the goals where Large Language Models (LLM) can have an effect, for example, inventive substance age, complex language understanding, or natural language interfaces.
2. Select the Appropriate LLM:
– Pick a deeply grounded LLM, for example, GPT-3, which shows progressed language age capacities. Guarantee that the chosen model lines up with the complexity of the projects you intend to achieve.
3. Adapted Pre-trained Models:
– Influence the exchange learning abilities of LLM. Instead of training without any preparation, use pre-trained models and fine-tune them for explicit assignments, reducing the requirement for broad training data.
4. Explore Innovative Applications:
– Think outside conventional applications. Use LLM for experimental writing, content creation, and projects that demand a fine and logically rich language generation.
5. Consider Computational Resources:
– Recognize the computational demands of LLM. Guarantee access to strong computational resources to work with the training and organization of large-scale language models.
6. Integrate with Existing Systems:
– Flawlessly integrate LLM into existing frameworks or work processes to upgrade their abilities. This integration guarantees that the model contributes decidedly to general business processes.
7. Stay Refreshed with Model Advances:
– Stay up to date on progressions in LLM innovation. As the field advances quickly, staying refreshed permits you to use the most recent highlights and progress for continuous heavenly outcomes.
By following these points, businesses can burden the power of NLP and LLM to accomplish excellent outcomes tailored to their particular requirements. Whether it’s through upgraded language understanding, opinion investigation, or innovative substance generation, these advancements offer colossal potential for many applications.
Are you excited to convert your data into actionable insights?
Conclusion
While NLP and LLMs both deal with human language, they contrast in their approaches. NLP focuses on algorithmic modeling of language for explicit assignments. It succeeds at distinct tasks like interpretation and information extraction through tailored models.
Simultaneously, LLMs use gigantic pre-training for expansive capacities yet less fine-grained control. LLMs exhibit great open-domain capacities however need full language appreciation. These fields cross over and complete one another, with new strategies combining their assets. However, NLP and LLMs can likewise present risks while may not be dependably evolved and applied.
Looking forward, the direction of Natural Language Processing versus LLM points towards more fine LLM AI interactions, deeper integration into different industries, and continual improvements in AI morals and innovation.
Focusing on capable improvement will be needed as language models continue to progress. Staying informed about their progress can assist organizations with designing viable and moral applications. Hire AI developer from A3Logics, an artificial intelligence development company that stands prepared to help. Reach us to investigate how these advancements can be tailored to your requirements, ushering in another period of AI-driven solutions.
FAQ
1. What is the essential distinction between NLP and LLM?
– NLP focuses on understanding and processing human language, while LLM, like GPT-3, goes inconceivable to produce human-like text, exhibiting advanced language generation capacities.
2. How do NLP and LLM differ in terms of scope and applications?
– NLP is worried about language cognizance, feeling analysis, and explicit tasks, while LLM reaches out unbelievable, excelling in imaginative language age and a large number of uses.
3. What kind of training data is required for NLP and LLM?
– NLP is in many cases trained on specific datasets tailored to the application, while LLM, as GPT-3, is trained on enormous and different datasets, learning examples and designs from different sources without task-explicit data.
4. Can NLP and LLM be fine-tuned for specific tasks?
– NLP might require fine-tuning for explicit projects and domains to upgrade execution, while LLM displays move learning abilities, reducing the requirement for broad fine-tuning because of its expansive understanding of language.
5. How resource-intensive are NLP and LLM?
– NLP for the most part requires less computational resources compared with LLM. LLM demands huge computational power and resources because of the monstrous size of the model and training data.
6. What are some typical applications of NLP and LLM in business and technology?
– NLP finds normal applications in chatbots, opinion analysis, language interpretation, and data extraction, while LLM is applied in experimental writing, content creation, language interpretation, and different tasks demanding high-level language generation capacities.
Table of Contents


Anusha Sharma
Content Writer
Anusha Sharma is a creative and versatile Content Writer who excels in crafting compelling and informative content. With a keen eye for detail and a passion for storytelling, she effectively communicates complex ideas to diverse audiences, enhancing brand visibility and engagement.




