14 May 2025
In this digital era, a large number of businesses are increasing their dependency on data pipeline automation to gather, process, and make data-based decisions in an efficient manner. Enterprises can use automation to make fast decisions backed by data, make operations smoother, and compete with others who are striving to gain a competitive advantage.
It is a data pipeline that allows the data to move from one source to the storage and analytical tools automatically without the intervention of individuals and organizations. This pipeline is important for carrying out the process of data collection, ingestion, transformation, storage, and visualization.
The ascension of the data pipeline automation segment can be inferred from the fast market growth it experiences. As the Fortune Business Insights report reads, the global data pipeline market will expand massively from USD 12.26 billion in 2025 to USD 43.61 billion in 2032, at a Compound Annual Growth Rate (CAGR) of 19.9%. Similarly, the US data pipeline tools market will be as high as USD 8,693.0 million by 2030, growing at a CAGR of 24.7% from 2025 to 2030. (Source: Grand View Research)
The adoption explosion is the direct result of the following: the demand for real-time analysis of data, the cloud’s rise in power, and data manipulation and interpretation taking more leading roles in decision-making processes. The data pipeline tools attract users by offering people efficient, accurate, and accessible data management of their own.
In this blog, we are exploring the basic principles and methods that data pipeline automation use cases. We shall look at the nitty-gritty details of data pipeline automation, such as how it functions, the advancements it offers, and many more.
Table of Contents
What is Data Pipeline Automation?
Data Pipeline Automation means setting up software tools and frameworks to manage, monitor, and optimize data fluctuation in between varied systems without human interference. The high-level purpose of this automation is to get seamless and reliable data collection, processing, and delivery from a source into a destination so that insights could be gained faster and decisions efficiently taken.
A contemporary business, working with massive volumes of data from diverse sources-applications, sensors, websites, and more-expects to have them flow around. Data flows through manual maintenance, being inefficient and error-prone. There arise automated data pipelines to keep life simple for these operations while maximizing the updated status and accuracy of data and making it easily accessible.
Key Components of Data Pipeline Automation
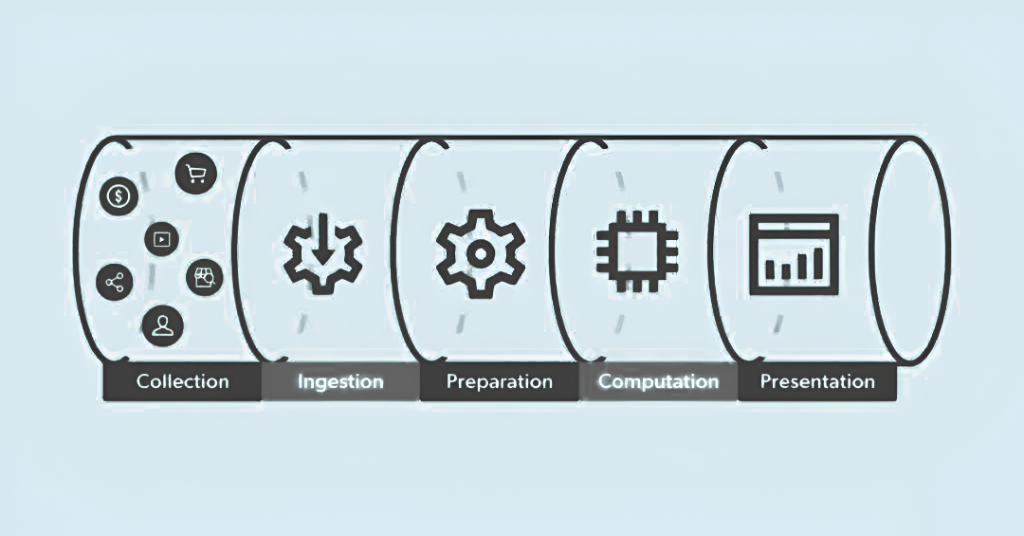
A data pipeline automation, when well-designed, contains several important parts, each of which contributes to the efficiency and reliability of the system:
1. Data Collection
At this stage, the pipeline is fed with raw data. Different data sources may be used to collect the data, such as API, database, cloud, IoT device, logs, etc. Automated tools, to some extent, continuously grab this data to form the pipeline.
2. Data Ingestion
After gathering all the data, the next step is to enter or load it into a central system. In a cloud data pipeline, this data-loading function is taken care of by various cloud platforms, such as AWS, Google Cloud, or Azure. Automation assures ingestion occurs in real-time or in scheduled sets with the lowest latency possible.
3. Data Transformation
Raw data almost never makes any sense or is functional in its original form. The transformation of the data, hence, involves cleaning, enriching, and structuring it for readability. This transformation step is carried out by automated scripts and tools that apply rules, filters, and mappings to prepare data for analytics.
4. Orchestration and Workflow Automation
At this level, all tasks in the pipeline are orchestrated and checked to ensure they are in the right sequence with workflow automation tools handling dependencies, retries, and errors, which are key factors when it comes to making a reliable automated data pipeline.
5. Data Storage
Once the data has been transformed, it should be deposited in a storage system that is accessible and secure for ease of future use. Such storage may be a data warehouse, a data lake, or a database, depending on the system’s actual structure. Pipeline automation not only automates the data store process but also helps ensure data consistency and data security with compliance regulations.
6. Data Presentation
Data that has been processed and stored should be presented in a way comprehensible to the user. Dashboards, reports, and APIs are used to provide data to the end user and to integrate data into applications. Automation keeps published data up to date and ensures that each channel has the latest, accurate insight as a reflection of reality.
7. Monitoring and Logging
Continuous monitoring and detailed logging help achieve the automation of the pipeline effectively. Fast failure detection, remediation of performance degradation, and elimination of bottlenecks are some of the benefits. Through automated alerts and logs, immediate visibility is granted into the health and efficiency of the pipeline.
Data Pipeline Automation is the foundation upon which the modern-day data infrastructure rests. With automated movement and transformation of data, for instance, a business can derive meaningful insights faster and in a more reliable manner. Companies that provide Data Analytics Services in more refined terms construct robust, scalable automated data pipelines that act as the backbone for business intelligence in addition to analytics and AI.
Why Automate Data Pipelines?
In today’s data-centered environment, companies have to be able to handle vast amounts of data really fast and with no mistakes. Manual processes just aren’t good enough to meet the demand, and so data pipeline automation has become a must for organizations that want to stay competitive and adaptable.
> Importance of Automation in Reducing Manual Effort
Without automation, data pipeline management is a process that constantly requires people’s involvement in tasks such as data collection, processing, and error handling. This will likely create major time lags, mistakes, and inefficiencies. By automating the pipeline, companies get rid of tasks that are repetitive and time-consuming, such as manual processes like data entry, cleaning, and transformation. Consequently, it reduces the number of human mistakes and frees up the company’s resources to undertake more strategic tasks. Therefore, the overall productivity is improved.
Automation of data pipelines also brings the benefit of consistent performance. As the automated workflows are executed according to pre-established rules, the chances of errors are limited. The method of data processing and delivery is highly repeatable, and without human input, the quality of the results remains high.
> Enhancing Speed, Scalability, and Reliability
One of the main advantages of automating data pipelines is that not only does it save time, but it also makes it much faster to go through the data. Automation enables data to be brought in, processed, and migrated to a storage system either instantaneously or according to a carefully planned schedule. As a result, the efficiency of decision-making is boosted considerably. For example, companies can benefit from the heightened data flow of either public cloud-based or on-premises systems by using automation that is not available when using manual methods.
Moreover, the handling of data is also better for further scaling. When the volume of data grows, the automation of data pipelines allows for completely drag-free overflow, or the need for fewer human resources and no manual handling. Therefore, the business gets to the heart of the matter and easily implements resources from various sources through the data management process. Also, adaptation to new tasks becomes easier.
Automated data pipelines, at last, provide reliability at a higher level. Businesses are equipped with instruments such as error handling, retries, and monitoring that are done in an automated way. Thus, all the setup can be adjusted easily to reveal and solve the existing issues, preventing downtimes and guaranteeing a continuous data supply.
Automating data pipelines will improve efficiency, minimize errors, and provide the speed and scalability needed for a modern data-driven corporation. Whether through data engineering services or futuristic cloud data pipeline methods, automation is the only way to execute dependable real-time data processing.

Classification of Data Pipeline Automation
Data Pipeline Automation can be classified in various ways based on processing methods, deployment data pipeline architecture, and transformation methods. Each classification identifies the most winning pipeline setup for a particular use case.
1. Based on Processing Methods
- Batch Processing Pipelines: They process data in batches, often on a schedule, and are useful for situations where data is not required to be processed in real-time. Geared toward heavy data processing work, they are often found in data warehousing.
- Real-Time Processing Pipelines: These pipelines work with data as it comes in, so that the data is immediately available for analysis. Up-to-the-minute data with fraud detection, for instance, really requires this kind of pipeline.
- Hybrid Processing Pipelines: The hybrid, as its name suggests, is a little bit of both and offers more versatility depending on the data requirement.
2. Based on Deployment Architecture
- On-Premises Data Pipelines: Such a data pipeline is deployed on the internal infrastructure of the organization, giving the owners complete control over the security and processing of data.
- Cloud-Based Data Pipelines: More information regarding Philippians will provide you with the flexibility, through an understanding of the context of the passage.
- Hybrid Data Pipelines: A cloud-based data pipeline is a platform accessed through the internet. Generally, the cloud data pipeline is the one that provides the technologies that house this pipeline in its facility. The cloud thus allows multiple organizational resources to be assigned according to project needs and is always accessible globally.
3. Based on Transformation Approaches
- ETL (Extract, Transform, Load) Pipelines: EJTLLVPIP Pipelines: Pipelines based on ETL [Extract, Transform, Load], i.e., they are networks that carry out the process of extraction, transformation, and loading. ETL pipelines enable data from a variety of different data sources to be accessed, transformed as required, and loaded into repositories.
- ELT (Extract, Load, Transform) Pipelines: ELT (Extract, Load, Transform) pipelines operate in the opposite way, as the first step is to extract the data. The extracted data is then loaded into a storage system, and only after that are transformations done.
- Stream Processing Pipelines: Stream Processing is an approach where the data on the stream is transformed as it moves through the system. This often leads to the emergence of real-time insights.
4. Additional Classification
- Data Quality Pipelines: Apart from the conventional task of collecting data, these pipelines have to ensure that the data is of good quality, clean, validated, and correctly transformed before use.
- Data Integration Pipelines: Furthermore, this set of pipelines automates the process of data extraction from numerous resources and their transformation into one single system that delivers the reports for the data.
Benefits of Data Pipeline Automation
The area of information technology uses data pipeline automation to perform jobs that emerge in both.
1. Enhanced Compliance and Data Governance
Automation refers to data that is processed in a way that makes it much easier to adhere to such standards and keep up with the requirements of data governance. By having automated data pipelines to do the job, you can assure that only the intended data is being accessed, and there is always a record to verify that.
2. Real-Time Data Insights
The automated pipelines ensure that data is instantly available and that it keeps pace with. This, in turn, provides the business with the foreknowledge to quickly decide on issues based on the most recent information, thus achieving fast-paced decision-making by the business or enterprise.
3. Dynamic Data Handling Capabilities
Automation can be used to deal with many other formats and multiple sources of data. These systems can be expanded with no difficulty as data volume increases and can also be transformed to handle the job needed on that day, no matter the conditions, thus giving the user the opportunity to switch off any system without interrupting work in the other running systems.
4. Cost and Resource Optimization
Businesses can cut the amount of work and lower their labor costs by getting rid of manual data handling. By doing so, unnecessary consumption is limited; thus, only the tools necessary for the given operation are used, and that will, in return, lead to the efficient processing of data.
5. Improved Data Quality and Consistency
Having everything automated will help prevent further issues and ensure the same data is in its correct state by just applying the same validation and transformation rules. This will lead to the highest quality possible for data that is less likely to contain mistakes and is kept current and reliable for analysis.
6. Simplified Workflow Management
The automated workflow system in the pipes simplifies the management of complex workflows quite significantly. This means that most jobs, like data extraction, transformation, and loading, can be completed without human help. This makes the process more manageable, and you can immediately see if there is a problem.
7. Quicker Analytics Time-to-Market
A fully automated data pipeline can speed up the whole process, starting from data collection to analysis, and hence deliver information more quickly. As a consequence, it is the industry with a faster time-to-market for analytics that allows companies to go in front of their competitors.
So, data pipeline automation makes no difference to data management, enhances efficiency, supplies timely, accurate insights, and does not hinder the reduction of costs incurred and the optimization of resources.
Data Pipeline Automation Use Cases
Data pipeline automation has been known for its ability to create a different environment in which a variety of industries can operate more efficiently. Also, it has been a significant step towards quick decision-making.
Here are some notable data pipeline automation use cases.
1. Enhanced Business Intelligence Reporting
By automating data pipelines, data that is supposed to be used in BI tools to make reports is updated and transformed without interruption. Thus, businesses are able to automatically access current, exact reports that provide them with information about the performance of the product, find out the trends, and view the key metrics. Thus, the teams can decide on the data-driven performance.
2. IoT Data Processing
Continuous data generation by the IoT devices causes a lot of data to need to be handled. Automated data pipelines can manage the collection, transformation, and storage of the data so that it will be in real-time. This acts as an excellent opportunity for businesses to supervise the devices, keep track of their performance, and also take action once issues arise. This applies not only to the data but also to the operation of bumper stocking.
3. Generating Comprehensive Customer Insights
Through the automated pipeline, a company can merge data from multiple sources like web interactions, sales, and customer service. This gives the company a more complete profile of the customer and allows them to do things like make offers based on the customer’s behavior, improve the service offered to customers, and optimize marketing strategies, among others.
4. Data Preparation for Machine Learning Pipelines
Prior to developing a machine learning model, data must be cleaned, transformed, and formatted in the right way. Automation of data movement has the effect of making the guidance more efficient. Consequently, the accuracy and effectiveness of predictions are improved by ensuring the availability of high-quality data.
All in all, data pipeline automation is good for business intelligence that is better and faster, real-time IoT data processing support, customer insights empowerment, and machine learning data preparation. These are the factors that help companies achieve more significant business values.
Best Practices for Automating Data Pipelines
Following these practices recommendations will make your data pipeline automation efficient, reliable, and secure:
1. Designing Modular and Scalable Architecture
Independently working components of the modular data pipeline architecture easier handling and scaling. Please design your pipelines with a flexible mind capable of accommodating increasing data volumes and new sources without undergoing massive architectural changes.
2. Ensuring Data Quality at Every Stage
Well, the quality of data is accommodating from the very start. Implement checks for data quality at every stage of collection, transformation, and loading so that only accurate, relevant, and cleaned data are allowed to go through the pipeline.
3. Continuous Monitoring and Alerting Systems
Automated monitoring of pipelines’ performance should be configured so that it detects changes and simultaneously alerts relevant officials. Alerts should always be configured to inform technicians of any failures, cause delays in resolving the issue immediately, and identify any presiding bottleneck.
4. Regular Performance Optimization
Performance Optimization is an ongoing activity whose aim is to keep the pipeline working at its best efficiency in terms of least processing time, elimination of all processes that are not required, and being able to manage extreme data load on the system without slowdown.
5. Supporting Incremental and Parallel Processing
Incremental processing is highly automated and fast because only new data and changed data are processed. Parallel processing speeds up the flow of information by executing multiple tasks simultaneously.
6. Following Security and Compliance Best Practices
Ensure that the pipelines comply with the laws of security and privacy. Encrypting data, access control, and auditing need to be performed to preserve the data’s integrity from any unlawful exposure and to satisfy industry standards.
Following these best practices will ensure the automation of data pipelines is smooth, with high-quality data supplanting secure systems that are scalable to meet a growing business demand.
Common Challenges and How to Overcome Them
Data pipeline automation has some benefits, but it also faces some hurdles of its own. Let us consider some common challenges and how to overcome them:
1. Managing Pipeline Complexity
Pipelines compound in their complexity as the size increases, thereby obstructing their maintenance. To overcome this, employ modular and extensible designs that fragment the pipeline into smaller, manageable components. This not only helps with troubleshooting but also provides flexibility when the pipeline changes in the future.
2. Handling Diverse Data Sources and Formats
Data vary in form, from structured to unstructured to semi-structured. Use versatile data integration tools that can deal with these formats. Also, a universal data transformation layer should be implemented that standardizes these data before processing them.
3. Minimizing Latency and Data Loss
To avoid delays and data failure, ensure your pipeline is perfectly set for real-time or nearly real-time processing. Techniques like incremental loading and parallel processing should be used to speed up data flow and prevent data blockage. The other part of this is error handling, which is trustworthy and can be used for the recovery of forgotten or incomplete data.
4. A3Logics Strategies to Mitigate These Challenges
At A3Logics, our main goal is to develop effective, scalable, and future-ready pipelines concentrated on rich monitoring and automatic testing to detect issues early. Our experience in cloud data pipeline solutions not only lies in ensuring high performance but also guarantees the seamless integration of various data sources. Our use of the most modern tools and technologies also helps us to handle the latency, ensure data cleanliness, and reduce the complexity of the pipeline, hence providing you with trustworthy and quickly delivered data.

A3Logics Data Pipeline Automation Expertise
At A3Logics, we primarily focus on establishing powerful and efficient infrastructural data pipeline solutions that efficiently aid businesses in the management, processing, and utilization of their data.
Our hands-on experience allows us to provide you not only with the technology of your existing systems but also with the reliability and high performance of the pipelines that our team builds and integrates with your systems. Our services help you with the timely processing of batch or real-time data that is secure, of high quality, and compliant with regulations.
Key Highlights of A3Logics Expertise:
- Our designers design the data pipelines that are tailor-made to suit the needs of the particular business.
- Our team is mastering both the cloud and premises areas as far as data pipeline architecture is concerned.
- Our developers are creating frameworks that grow along with your data and business needs.
- We are always careful in data validation and transformation to guarantee that data is both clean and accurate.
- Our skilled developers have the ability to process data in real-time or almost real-time, which makes decision-making faster.
- Our professionals’ installation of continuous monitoring and alerting systems to solve emerging issues proactively.
Conclusion
In a world where business is so fast-paced, pipeline automation is necessary for quick and effective data handling. Once automated, manual work can be reduced, data quality is enhanced, insights can be delivered in real time, and operations can be scaled and maintained on a budget.
Yet, the automation of data pipelines poses plenty of challenges- a complex environment, various sources of data, latency concerns, among others. Businesses that put these best practices into action or expand on expert services offered by A3Logics thereby ensure their data pipelines become dependable, secure, and ready for growth.
In the end, data pipeline automation smoothens operations and allows businesses to concentrate on making faster, smarter decisions with real-time, high-quality data.
FAQs
Table of Contents





